
需要准备的工具:
1、浏览器(谷歌或者火狐都行,但推荐火狐,火狐的开发者模式比较友好)
2、Python环境 + PyCharm(语言仅是一种工具)
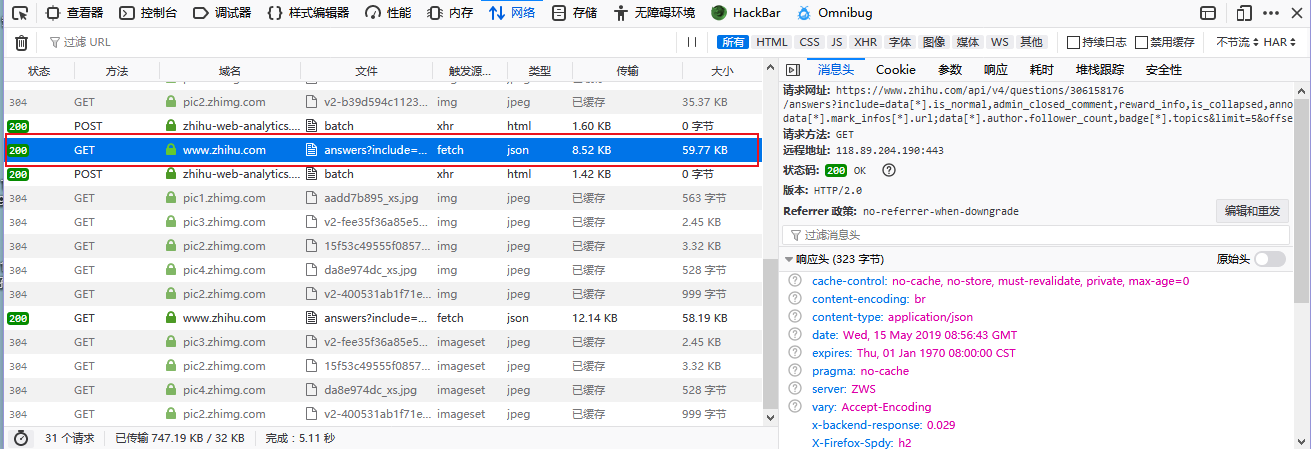
首先,我们通过浏览器访问知乎的任意一个回答下的帖子,此处我访问的问题是“浙江的你,择偶的标准是怎么样的”,(问题这个没有做任何要求,任意问题都行),然后按下浏览器的F12键,启用开发者模式,将选项卡中切换至网络模式,然后不断的下拉问题,截取它的网络封包,如下图
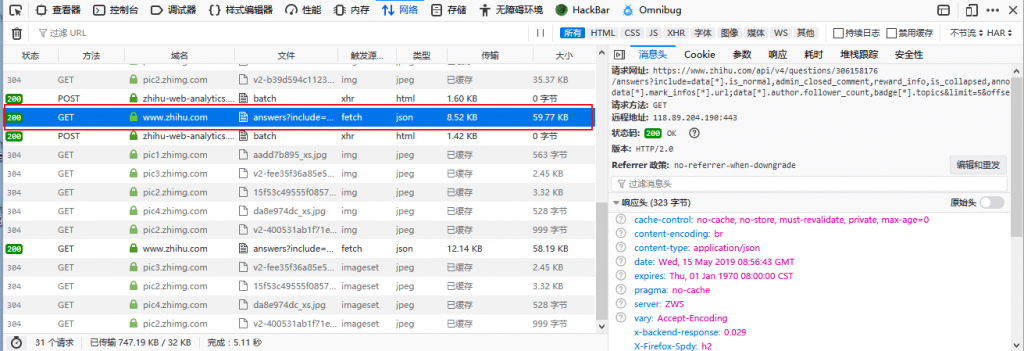
分析的大致思路是这样的:优先查看POST数据包或者json请求数据包,最后是查看js,html类型的文件,当选中一条请求数据之后,右边就会弹出一个详细的请求过程窗口,按下编辑和重发,便于分析可用数据。
由于是GET请求,所以取出如下几个参数,用于分析
1、Host(用于请求目标主机的URL)
2、U-A(浏览器标识)
3、Referer(部分网站会参照Referer值来验证数据包是否有爬虫标识,如网易)
4、Cookies(身份验证状态码,由于此处我检索触发的数据包请求是“游客状态”下的,所以此处的Cookies应该作用不大)
分析HOST可以得出,limit和offset两个值可以更改,可能sort_by的参数也可做更改不过在不确定sort_by有多少参数的情况下,我还是不改了….
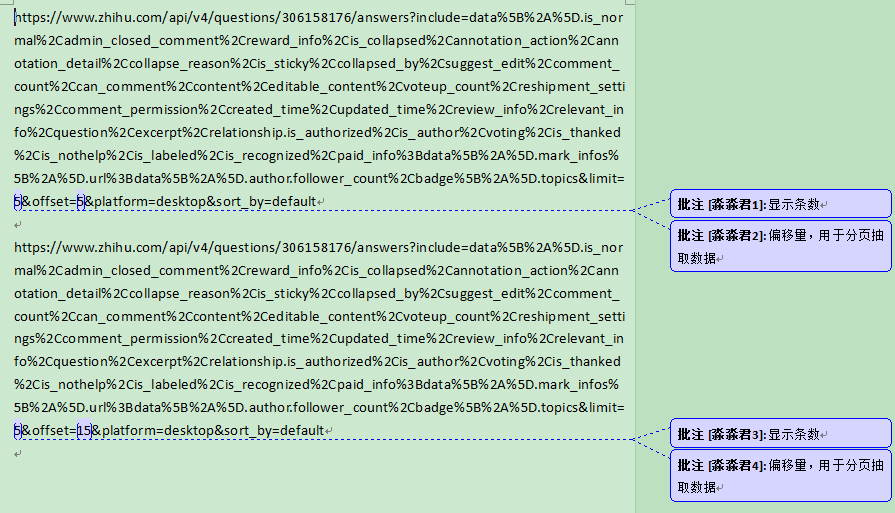
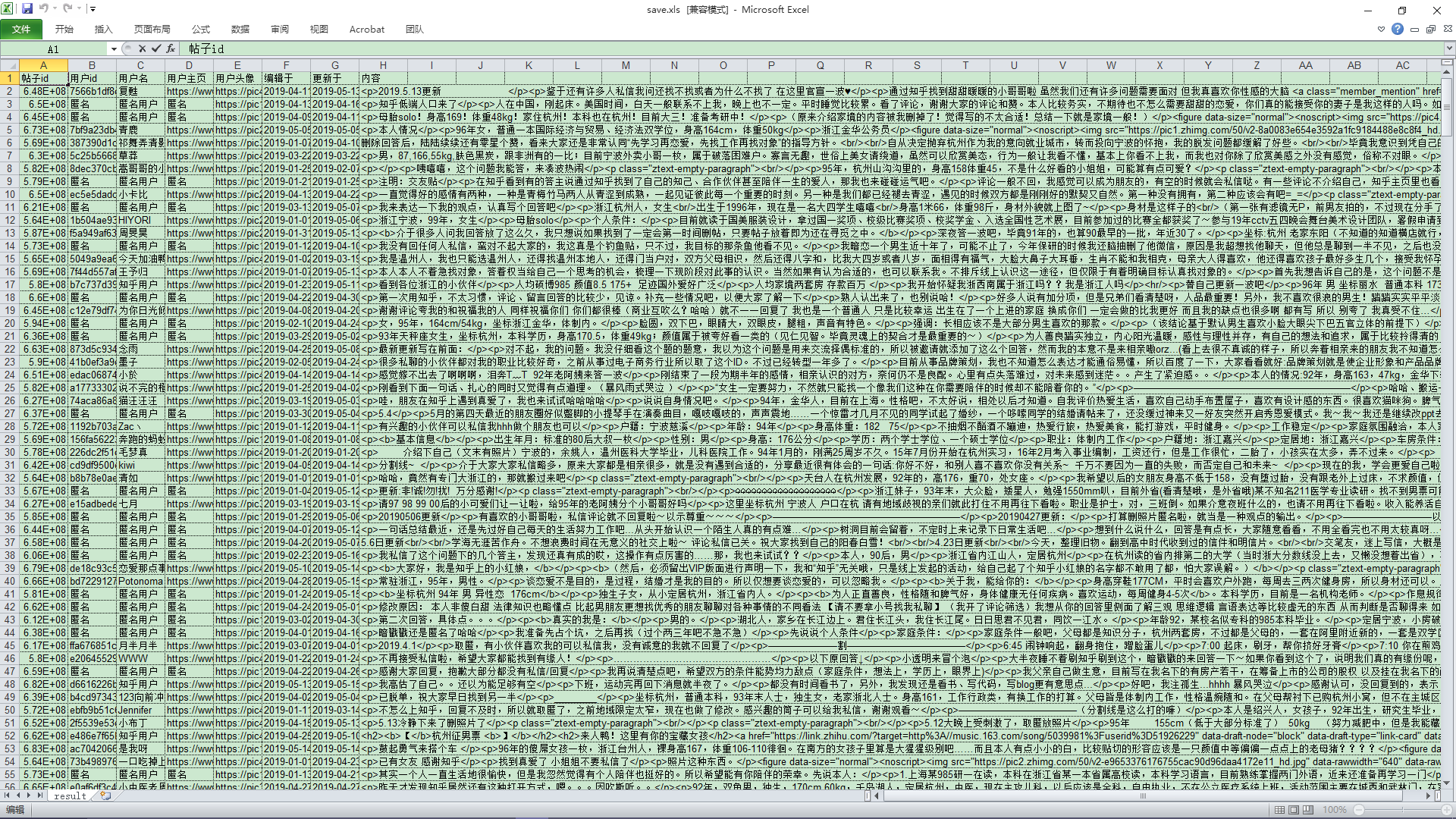
访问这些host地址后得到了如下结果:
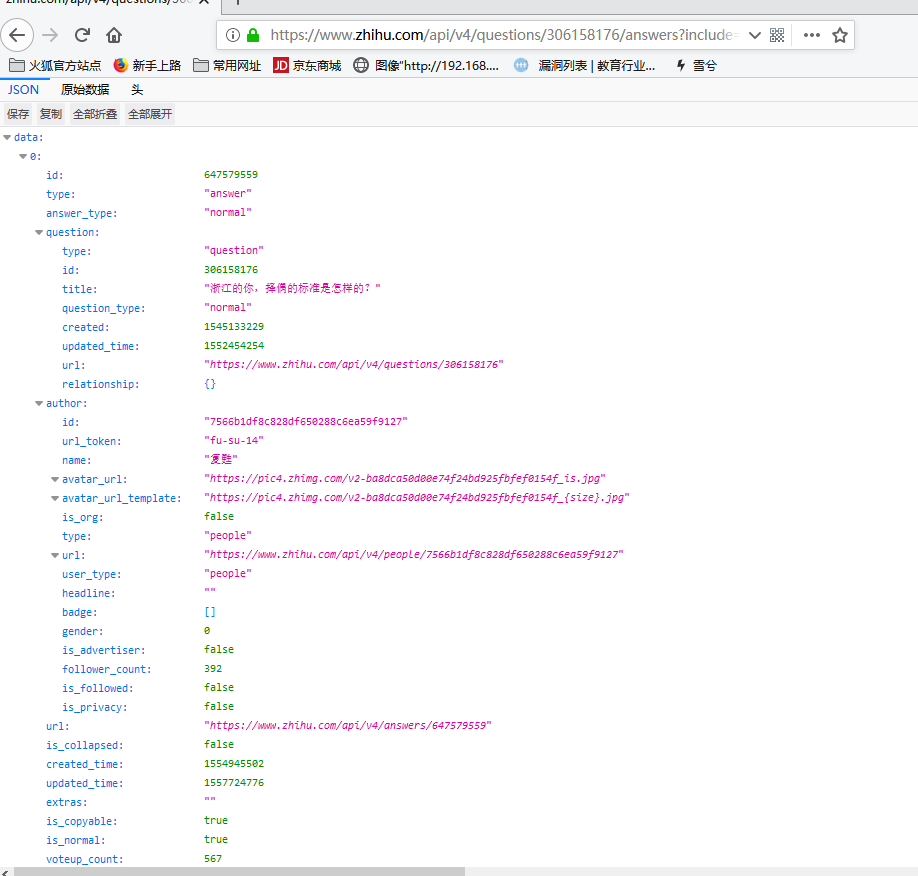
确定无疑了,这些json数据就是我想要的,hhhh…对于json数据的分析就不展开了,有兴趣的小伙伴可以去百度一下json基础入门,那就直接开始Pythoning吧,以下是代码篇!….
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
import requests; import json; import time; import xlwt; def get_jsonstr(page,qid):# parameter1 = pages,parameter2 =question_id,page>=0 headpar = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'} req = requests.get( 'https://www.zhihu.com/api/v4/questions/'+str(qid)+'/answers?include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_labeled,is_recognized,paid_info;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics&limit=5&offset='+str(page)+'&platform=desktop&sort_by=default', headers=headpar); req.encoding = 'utf-8'; return req.text; def isext(src,list):# 是否存在鸭 if(list.__len__()==0):return True; flag = False for i in list: if(i in src): return True li_keywords=['绍兴','越城',"宁波","湖州",'长腿',"美食","做饭","本科"];# 您的择偶标准,例如:如果该列表为空 则显示当前问题下的所有回答!我是不是暴露了我是个腿控?!....别误会啊~我不是变态 li_save = []; book = xlwt.Workbook(encoding='utf-8',style_compression = 0); sheet = book.add_sheet('result',cell_overwrite_ok = True); temp =["帖子id","用户id","用户名","用户主页","用户头像","编辑于","更新于","内容"] for x in range(temp.__len__()): sheet.write(0,x,temp[x]); # 初始化表 line = 0; items = int(json.loads(get_jsonstr("1","306158176"))['paging']['totals']);#取出 服务器端当前话题下有多少条回答 for i in range(0,items,5): print("正在爬取第"+str(i)+"页.......") jsonstr = json.loads(get_jsonstr(i,"306158176")); if(str(jsonstr).find("系统监测到您的网络环境存在异常,为保证您的正常访问,请输入验证码进行验证。")!=-1):#同一公网请求次数过多之后,知乎会屏蔽你的,过一段时间或者换个网即完事 print("数据异常,请稍候再试"); break; for j in range(0, len(jsonstr['data']), 1): # 解析每个请求返回的json数据包 tid = jsonstr['data'][j]['id']; authorid = jsonstr['data'][j]['author']['id'];#批量解析各个有用的参数,作者id,作者头像,作者内容 等等... addr = "https://www.zhihu.com/people/"+ str(jsonstr['data'][j]['author']['url_token']) + "/activities"; if (authorid == "0" or authorid == None): authorid = addr = "匿名"; if (isext(str(jsonstr['data'][j]), li_keywords)): line+=1; li_save.clear(); li_save.append(tid);# tid li_save.append(authorid);# aid li_save.append(jsonstr['data'][j]['author']['name']);# author name li_save.append(addr);# home address li_save.append(str(jsonstr['data'][j]['author']['avatar_url_template']).replace("{size}", "xl"));#img li_save.append(time.strftime("%Y-%m-%d/%H:%M:%S", time.gmtime(int(jsonstr['data'][j]['created_time']))));#created_time li_save.append(time.strftime("%Y-%m-%d/%H:%M:%S", time.gmtime(int(jsonstr['data'][j]['updated_time']))))#updated_time li_save.append(jsonstr['data'][j]['content']);#content for k in range(li_save.__len__()): sheet.write(line, k, li_save[k]); # 设置表的值 print(line, k,li_save[k]);# 显示细节性爬取,亦可以屏蔽 book.save('C:/Users/小太阳/Desktop/save.xls');# 最后保存到哪里..此处我保存的是桌面 |
以下就是知乎数据爬取后的结果图:
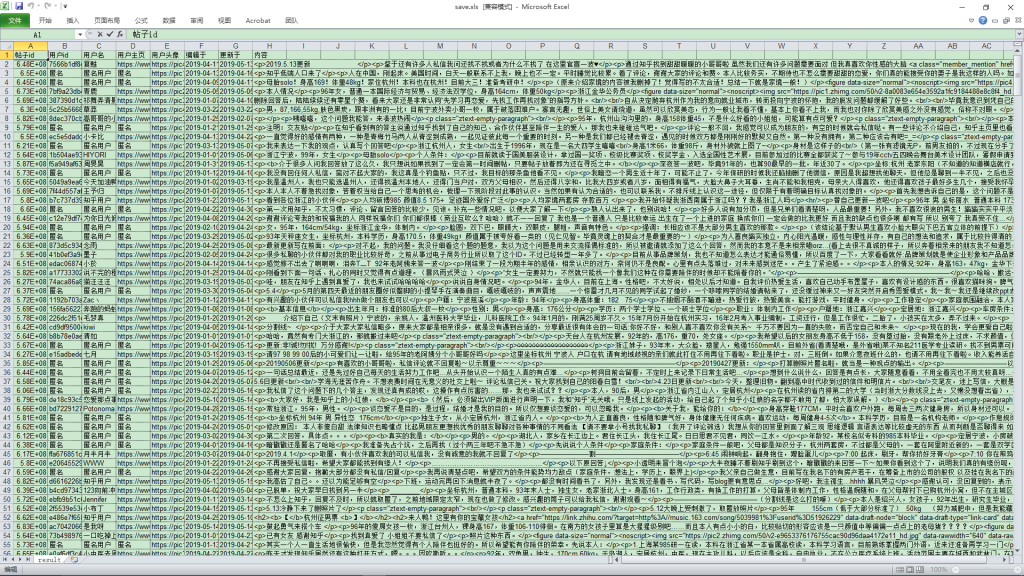
本人菜鸡一只,如果您有什么更好的思路或者算法,烦劳发送至snowion@qq.com,一起成长一起进步鸭
伽蓝君
2019.5.16